テレワーク増加で期待される自動議事録作成サービスにおいて重要な「話者認識」について
2020.05.26
話者認識への期待と関連市場
以前(2019/10/27)のコラムにて、話者の発話を文字に起こす音声認識について特集したが、今回はその内容について、さらに深堀した。
一見すると前回のコラムの結果では、一般的には音声認識精度はある程度高い水準となってきていると評価できるように思う。しかしながら、実際の会話では、多くの人間が同時に話しており、一人で発話するようなクリアな音声が必ずしも取得できるわけではない。
現在「POCKETALK」などの音声翻訳デバイスの普及が急速に進んでいる。それらのデバイスの大半は、ボタンを押し、本体マイクにどこからどこまで誰が話したのかが、デバイス側に明確に提示される。
また昨今では、自動の議事録作成サービスの導入などが進められており、新型コロナウィルスの影響によるテレワークやWeb会議のような遠隔会議の広がりから、今後一層の導入拡大が期待される。そういった中で、より精度の良い音声認識や、文字起こしされた文章の発話者を特定する話者認識の需要はさらに高まっていくと考えられる。
文章の要約や文章理解に基づく文字ベースでの対話型アプリ(チャットボット)など、テキストに起こされたデータに対する処理性能は年々向上している。その一方で、基盤となる音声認識については、多くの会話情報を集めて、汎用的な音声認識AIを作成する手法がスタンダード化している。そのデータ収集の難しさやコスト面から、既存の音声認識サービスをバックグラウンドで利用することで、新たな音声認識アプリの開発などを行う企業も多い。
そのため、今回は以前のコラムで紹介した文字起こしに続き、『誰が何を話しているのか知りたい』というニーズに対して、「話者認識」を前回同様に大手クラウド4社の音声認識サービスがどの程度応えることが出来るのか、電話やWeb会議での会話音声を対象に検証してみた。
各社音声認識サービスにおける話者認識機能の状況
現段階において、日本語対応しているものはAWS、GCP、IBM Watsonの3社である。
(※Azureについては、現在(2020/05/21)日本語未対応)

<AWS>
長所
・文字起こしする時間が比較的短い。
短所
・相槌などで切れ目がないと同じ話者がずっと話していると判断してしまう。
・精度向上のためにおおよその話者人数設定の必要がある。
→指定した人数の上限に達した状態で、第三者の声が入ってしまった場合、声質の近い人間をまとめて1話者として処理してしまう。また、話者数の指定が多いと、声のトーンが変わったり、ノイズが入ったりと、タイミングで話者が増えたと認識することがある。
<GCP>
長所
・AWSと比べ、若干GCPの方が早い結果となった。
短所
・AWSと同様な結果となった。
<IBM Watson>
長所
・相槌などの一瞬のものについても、対応できている印象を受けた。
・GCPで検出していた待ち時間のBGMの誤判定がなかった。
・話者の人数指定の必要がない。
短所
・Web会議や電話の通話音声については、あまり文字起こしの精度が高くなかった。
→ハウリングなどのノイズが入ると文字起こしの精度が低くなる傾向がある。
AWSとGCPとIBM Watsonの検証結果比較(項目毎順位)
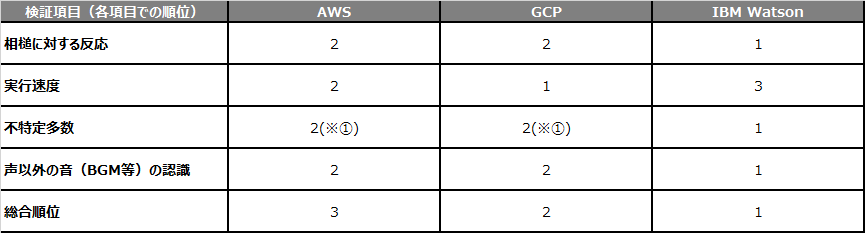
※①仕様上、話者人数を正しく指定していれば、人数に対応できるが、話者が3人登場するデータで、2人しかいない設定にするとうまく分離できない。
まとめ
今回、大手クラウドサービスの話者認識機能について、日本語対応のある3社の機能を比較した。
今回行ったweb会議や電話の通話音声を対象とした検証では、AWSとGCPはほとんど特徴が似通っていたが、処理の実行時間の点で、GCPの方が順位が上となった。また複数人会話の話者認識精度の点で、IBM Watsonが他の2つと比べて総合得点が高い結果となった。