本社エントランスに画像認識を導入してみた
2019.07.29 AI

はじめに
本コラムでは、定期的にAIの社会実装や最新学術研究等について、定期的に発信していく予定です。
当社が事業として取り組むAI分野は、日々新たな学術論文が発表される非常に移り変わりの早い分野です。
また、それらの技術をビジネスの現場において、どのようにお客様課題に結び付けていくかが課題となっております。
当社では、そうした技術のキャッチアップを通じ、お客様へのより良い提案のための技術の蓄積を行っております。
コラム記事の特集の中では、そういった取り組みの一部を記事として、発信していきます。
画像認識の基礎
今回のコラムにおいては、自動運転・セキュリティなどともに、目にすることの多くなった画像認識の基礎技術について、記載してみました。
アノテーション
よく耳にするディープラーニングとは、深層学習とも呼ばれ、学習手法の一つであり、学習していない段階で画像認識を行うことは、出来ません。
まずはその画像に写っているものが何を示しているのかということを教える必要があります。
そこで重要なのがアノテーションです。
アノテーションをすることで、画像上のどこに写っているものが一体何を示しているのかを示す情報を画像と紐づけることが出来ます。
それらを大量に学習することで初めて、AIは画像認識が可能となります。
リアルタイム物体認識
自動運転など多くの技術で重要となるのが、リアルタイムでの物体認識です。
一般的にこれらの認識は、1フレーム単位で高速で処理することで実現しています。
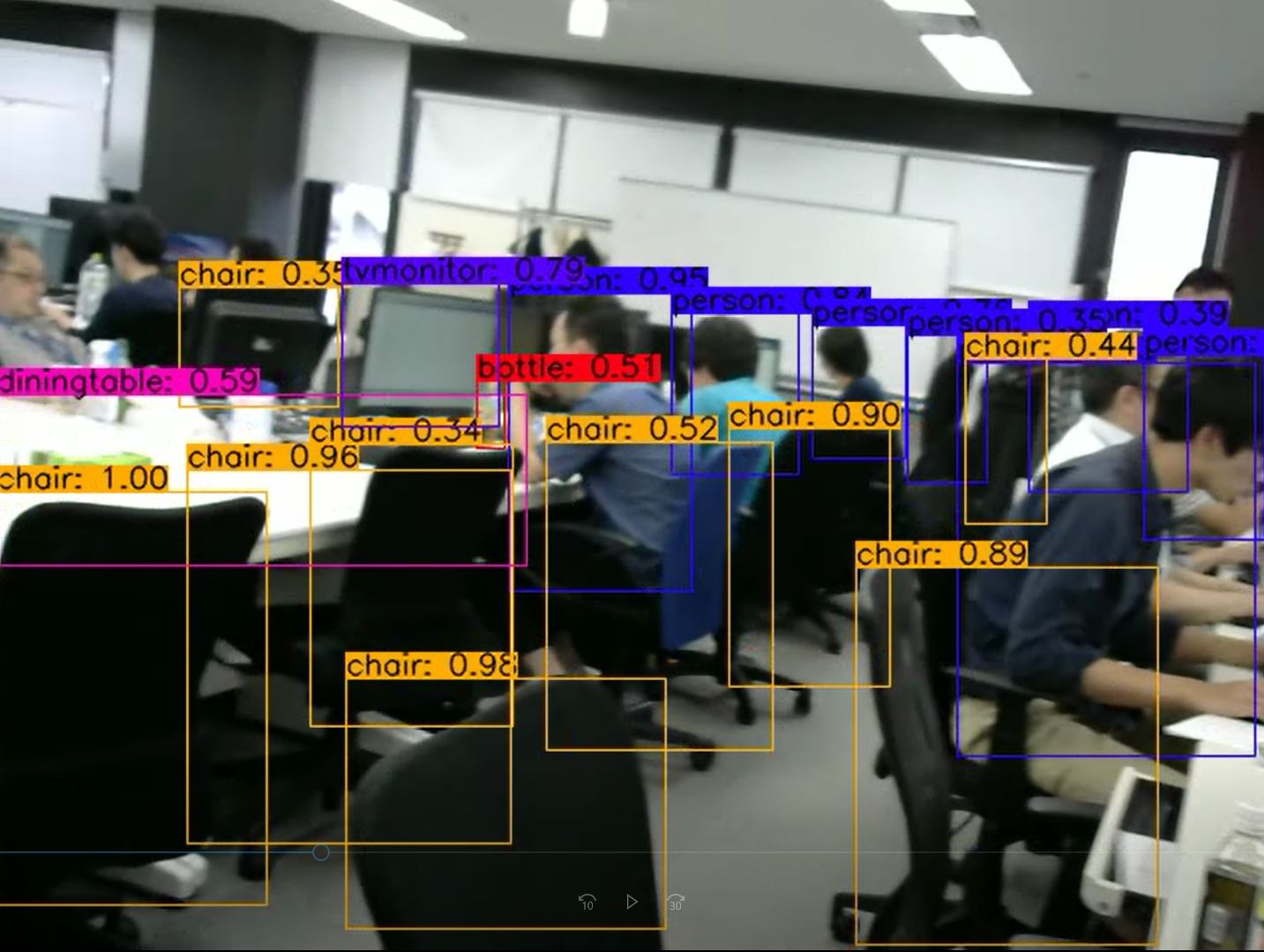
YoLoV3
リアルタイムでの物体認識において、有名な手法の一つがYoLo(You only look onceの略)です。
YoLoV3による物体識別
学習させた物体について、それぞれ物体名とその確率を表示しています。
かなりの精度で物体を識別できていることが分かります。
年齢・性別認識デモ
今回は本手法を基に顔を検知できるネットワークを作成し、さらに認識した人の顔から年齢や性別を認識する別のネットワークを組み合わせたモデルを実装してみました。
年齢・性別認識を行うモデルの構造は以下のようになっています。
今回作成したデモは会社エントランスのモニターに搭載してみました。
学習に使用したサンプルやカメラの解像度の関係で、遠距離や斜めからの年齢推定の精度はあまりよくありませんが、モニター付近であれば、比較的精度の高い推定結果が得られました。

